400-123-4567
400-123-4567
行使守旧形式做纰漏修复提效,只实用于斗劲简便的场景,例如遵循版本号判定行使的开源组件是否存正在纰漏○▲,更众高危境的如导致数据吐露的注入类纰漏/账密类等○○,该计划难以通用▲○。重要由来总结如下:
正在前文先容措置营业数据时,咱们提出借助于污点传达技能,只摘取纰漏触发点所能手的上下文代码。那么○,这个上下文取众少行适宜呢○?这里咱们正在推理阶段取差别巨细的上下文举行了测试○,如图8所示▲。从结果中可能看出○,差别巨细的上下文确实对结果有影响,而且关于差别纰漏○○,影响不太肖似▲。
腾讯混元项目组参考业界主流做法○,一共选用数十个数据纠合▲,分为中文NLP、英文NLP职司、代码、数学、AGIEval、CMMLU、CEval等维度○,归纳评估模子正在各项维度上的本事。个中,腾讯混元十亿级别大模子正在代码本事上的晋升加倍明显,这点与咱们行使中的精调体验也分外相同。
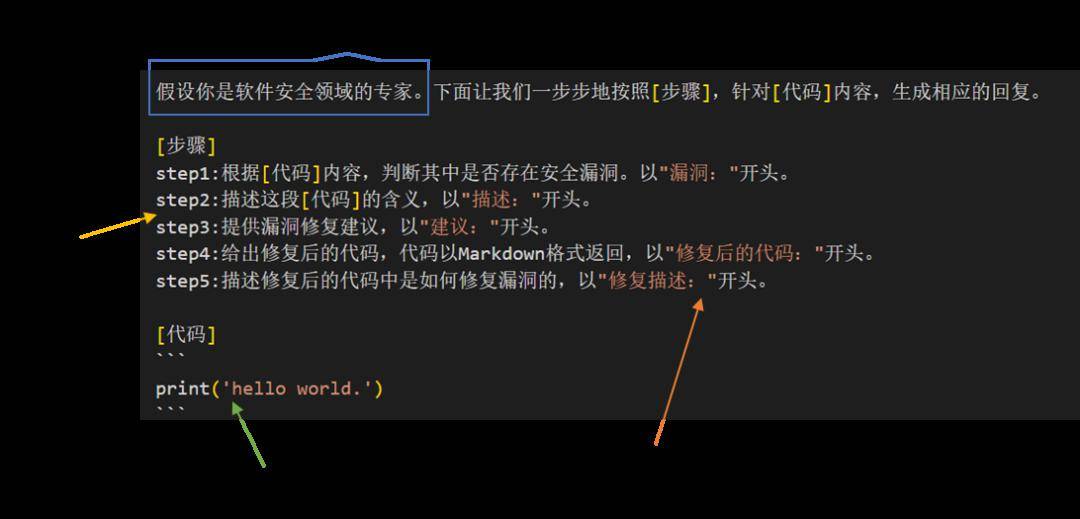
通过调理对模子提问的办法,使得模子的回复效益更好。全体的,咱们通过业界的论文以及体会分享,总结了一个相对通用的模板:expert+COT+输出体例+变量。如图5所示○▲。个中○○,expert是一种加强提示战术,用于指示LLM像专家相通回复题目。COT,即思想链,通过补充一系列中心推理程序○,能明显升高大型讲话模子纷乱推理的本事○○。
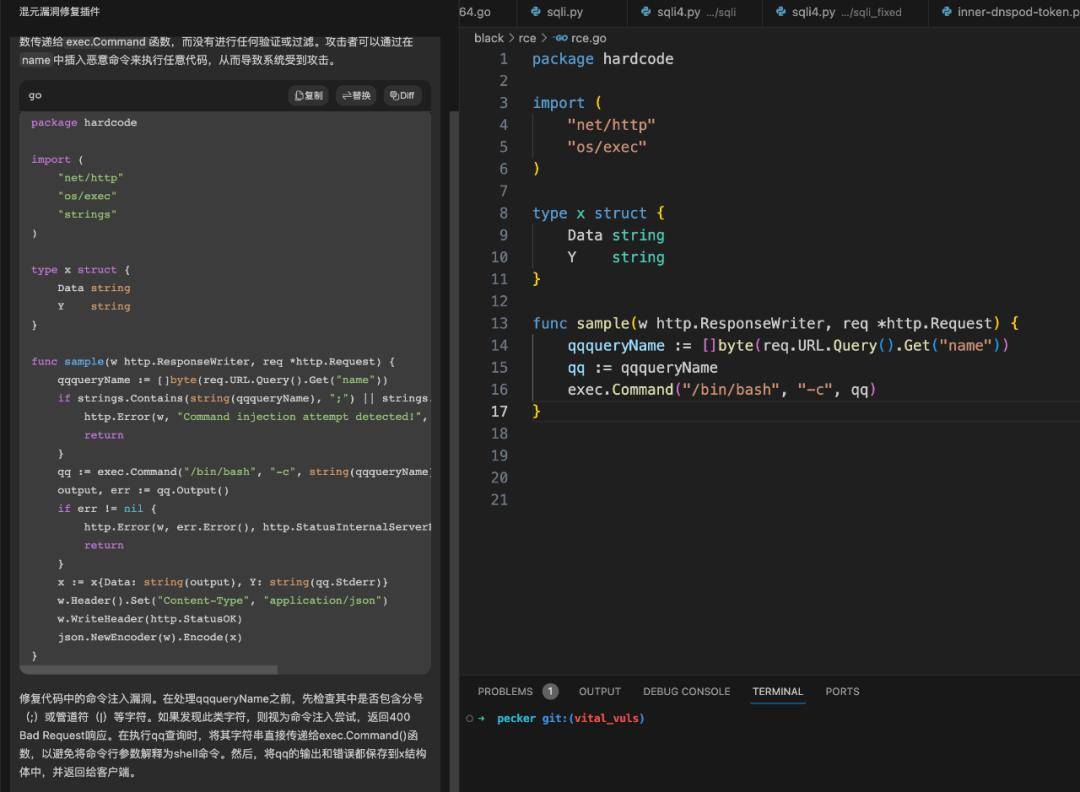
大模子纰漏修复插件是腾讯朱雀测验室正在平和垂类场景的一个首要实行。咱们祈望通过AI大模子,竣工研发平和场景的纰漏自愿修复,给出修复提倡并供给修复代码,助助更众开垦职员升高研发效用。正在腾讯混元大模子的接济下○▲,纰漏修复插件通过精调后摆设的私有化模子○,竣工了正在帐密硬编码、SQL注入、夂箢注入等纰漏类型的修复提倡输出和修复代码天生等功效○▲,竣工平和左移,更有用地正在编程中行使插件收敛纰漏危机。
各式基座大模子和代码类Codex大模子▲缝隙修复!腾讯混元大模子正在研发平安缝隙修复的试验j9九游会,,具有巨大的代码天生本事。这些模子可能清楚自然讲话指令,并遵循这些指令天生相应的代码。这种本事使得它们可能用于百般编程职司,席卷但不限于编写新的函数、修复代码中的失误、优化现有代码等。这些模子的代码天生本事基于其正在多量代码库上的锻炼。正在锻炼经过中○j9九游会,模子进修了百般编程讲话的语法和语义以及何如将自然讲话指令转化为代码。于是,只须给出分明的指令,这些模子就能天生相应的代码。但这些天生的代码中仍存正在少少平和题目,即:潜正在的不精确、含纰漏的代码等。于是,咱们须要行使大模子的代码天生本事○○,同时祈望通过精调等操作○,使大模子能有用修复纰漏代码,尽量天生平和无纰漏的代码片断。
三、混元一站式何如迅速定制司内自研的研发平和大模子 3.1 腾讯混元大模子本事 锻炼优化
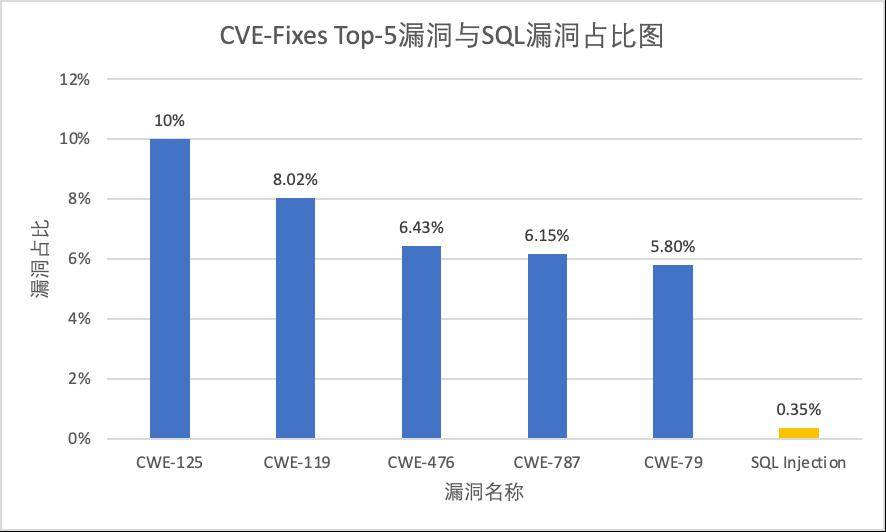
公然数据,更众指的是学术界开源的数据▲○。这类数据,依然被多量学术任务模仿行使○▲,自身具备必定的可托度。目前,咱们行使的重要是CVE-Fixes数据集○▲。
Github是主流开源社区之一,其史籍数据中含有多量的纰漏代码及修复的记实,但差别开垦者的编程秤谌七零八落。咱们遵循枢纽词召回与纰漏合系的数据,但实行中发掘大个人(90%)召回数据存正在与纰漏修复无合、失误的修复办法、代码质料低等等题目,于是咱们须要少少自愿化的形式来过滤这些数据。
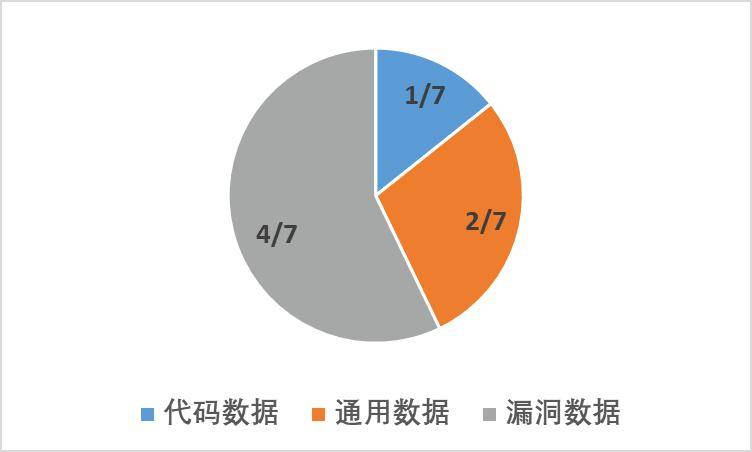
除了纰漏数据外,咱们还搜求了开源的通用、代码、数学sft数据集发平安缝隙修复的试验j9九游会,并举行了相应的配比测验。咱们发掘▲,数学数据集对纰漏修复确切率的晋升根基无影响,而适宜比例的代码、通用数据○,有助于晋升模子的纰漏修复确切率。
大模子纰漏修复插件是腾讯朱雀测验室正在平和垂类场景的一个首要实行。咱们祈望通过AI大模子,竣工研发平和场景的纰漏自愿修复,给出修复提倡并供给修复代码▲○,助助更众开垦职员升高研发效用。正在腾讯混元大模子的接济下,纰漏修复插件通过精调后摆设的私有化模子,竣工了正在帐密硬编码、SQL注入、夂箢注入等纰漏类型的修复提倡输出和修复代码天生等功效,竣工平和左移○▲,更有用地正在编程中行使插件收敛纰漏危机▲○。
关于SQL注入以及夂箢注入纰漏来说▲○,适中巨细的上下文有助于晋升测试确切率。当上下文过少时▲▲,模子抽取的与纰漏合系的语义新闻不敷,通过这些新闻无法判定是否存正在纰漏,导致确切率降落;相反○▲,当上下文过众时▲○,模子定位纰漏所能手或许存正在贫穷,导致确切率降落。
图8. 差别纰漏类型修复确切率随上下文长度的变换弧线 插件接济纰漏检测和修复
大模子具有丰厚的预锻炼语料新闻▲○,如:册本文档、代码素材、网页文本等等▲。基于预锻炼语料新闻,并对基座大模子举行垂类范围的精调,大模子能联结常识新闻举行整合和证明▲▲,发作有用的回答。关于研发平和场景来说,咱们不但须要天生有用的修复代码○,也祈望为更众的开垦同砚供给全体和明了的修复了解指引,从而更好地提效。
营业数据○,即搜求公司营业史籍修复数据○,洗濯后举动锻炼数据缝隙修复!腾讯混元大模子正在研。营业数据长处分外众○,最切近模子行使的场景、含有更契合公司营业场景的修复办法▲▲。但营业数据与GitHub数据有肖似的弱点○▲,洗濯难度较大○○。
基于上文获取的纰漏数据▲,咱们举行了多量的测验。正在数据总量和质料稳固的景况下,“Prompt工程”和“数据配比”对测验结果会发作影响。同时,咱们指出:差别笔直范围下获得的测验结论也许率差别,比如咱们正在数据配比时配比了个人通用数据和代码数据缝隙修复!腾讯混元大模子正在研发平安缝隙修复的试验j9九游会,,而其他团队或许只是用笔直范围的数据。于是,咱们提倡民众正在聚焦的笔直范围众测验、再总结。

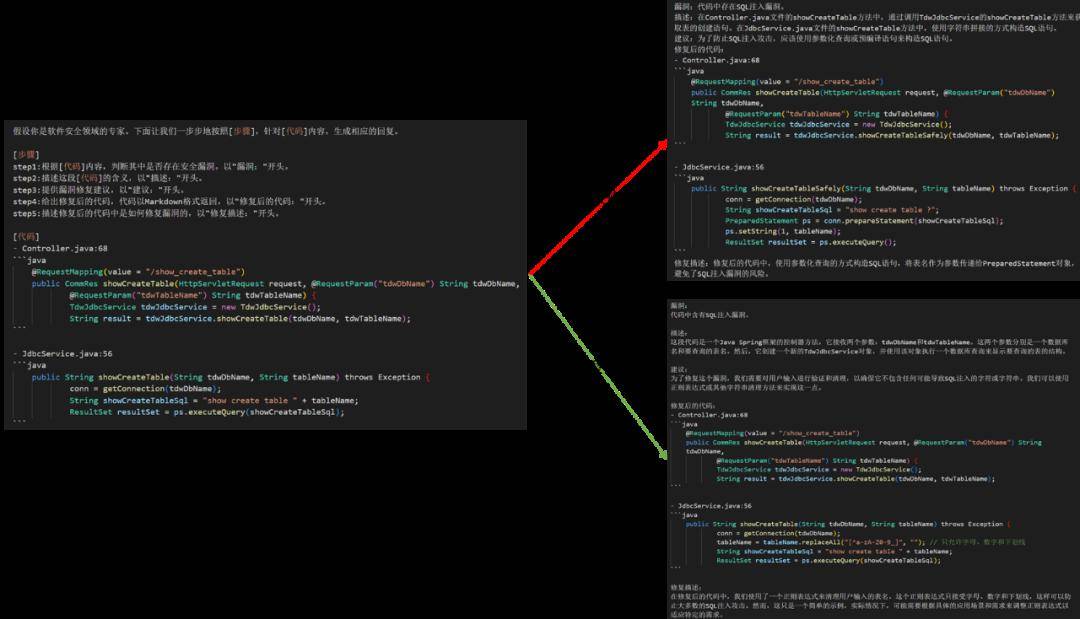
=号▲,导致语义的转变▲▲。于是咱们填充策画了一套规矩○▲,来判定修复前子女码语义是否有更改。
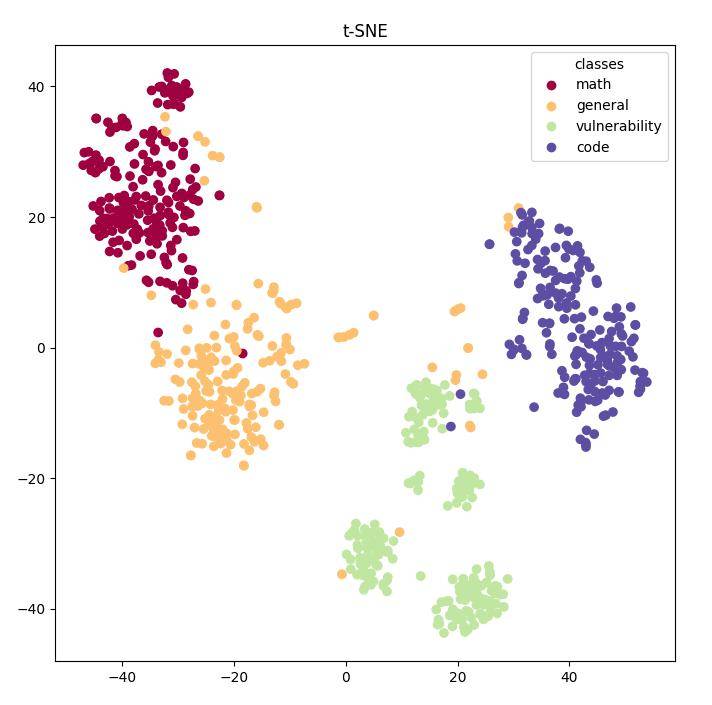
咱们将开源的通用(general)、代码(code)、数学(math)、纰漏(vulnerability)数据集▲,输入到模子中,抽取倒数第二层对应的embedding○,行使t-sne算法对其举行可视化○▲,获得的结果如图7所示。可能看到数学数据集隔绝纰漏数据集最远,这也证明了为什么数学数据集对纰漏修复确切率的晋升根基无影响。
腾讯混元大模子通过多量测验,对预锻炼数据举行了语料丰厚扩充,已笼盖 100 众种自然讲话,32 种编程讲话;并源委了数据洗濯、过滤、去重等流程,对各式数据举行了多量的数据配比测验▲○,包管了较为平定的锻炼经过○。同时,项目组关于长文本事、地点编码等技能细节举行了纠正和优化○▲。
咱们采用的纰漏修复数据源,包蕴GitHub数据、公然数据、营业数据等,数据质料按序上升▲。下面咱们大致先容各数据源的潜正在题目和措置经过。
2023年,大模子成为了各行各业的热门合心点○,个中平和垂类范围的平和大模子也涌现了百花齐放的态势,重要笼盖平和筹商、平和培训、平和监控、平和修复等本事。微软2023年3月份正式公布集成GPT-4的Microsoft Security Copilot▲▲,旨正在更好地供给平和器械和专家常识,辅助企业识别和检测平和危机▲○。谷歌2023年4月公布“谷歌云AI平和任务台”,行使 Sec-PaLM 来助助用户查找、总结和应对平和题目▲○。邦内公司也推出了自身独有的平和大模子,重要关于平和场景,供给专家级其它筹商提倡,提效运营效用。
通用大模子的兴起,依赖于大范围的数据灌输;大模子能否正在笔直范围落地,同样依赖是否有高质料的范围数据○。关于研发平和场景▲,咱们也堆集了体例且丰厚的高质料数据措置体会。
咱们将测验结果与gpt3.5举行斗劲,结果如外1所示▲○。从外1中可能看出,咱们的均匀确切率比gpt3.5高1.67%○○,全体到每个纰漏类型▲,均超越或持平gpt3.5。
关于帐密硬编码纰漏来说,测试确切率跟着上下文行数的增加而删除▲,揣测或许是由于关于该纰漏类型,较少的行数就足以让模子判定存正在帐密硬编码,也足以让模子举行修复。相反○▲,当测试上下文过众时,模子定位纰漏所能手或许存正在贫穷,导致确切率降落○▲。
比拟守旧秩序了解技能,大模子具备巨大的推理本事▲○,越发是正在代码天生方面出现超越,可通过锻炼来进修纰漏修复的形式和法则。
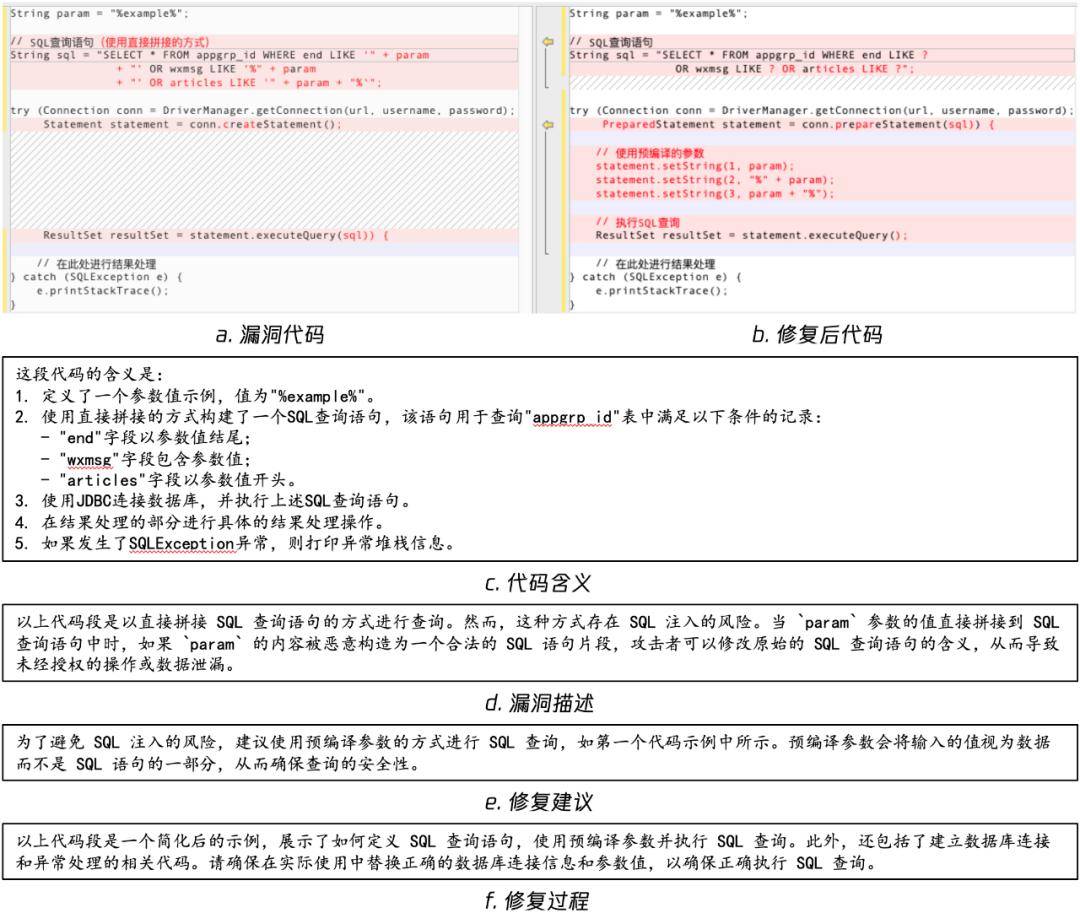
但正在实行经过中仅行使这三个人新闻来精调大模子▲,效益并欠好▲▲。为此,咱们扩至纰漏类型、纰漏代码、修复子女码、代码形容、纰漏新闻、修复提倡、修复经过七个属性,构成“纰漏代码 - 代码做了什么 - 存正在什么纰漏 - 应当怎样修复 - 修复子女码 - 全体修复经过”的满堂逻辑,实质锻炼效益更好。
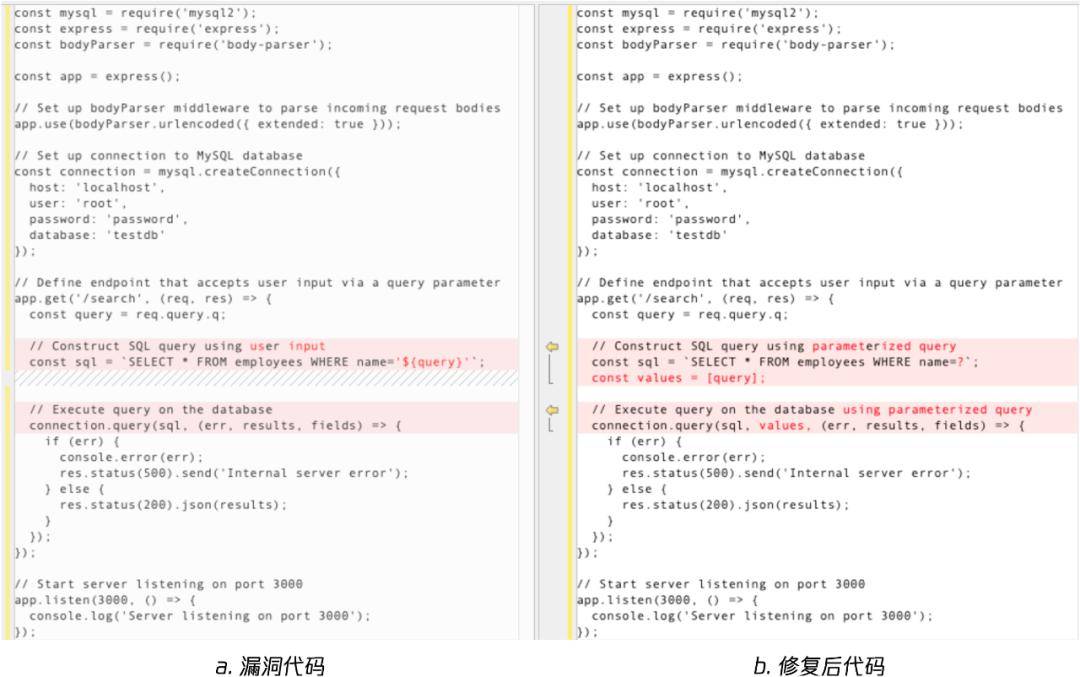
SQL注入、夂箢注入和账密吐露○○,并较业内大幅晋升发掘危机实在切性○▲。目前插件已接济正在vs code里手使,仅需正在vs code内安置插件,即可竣工正在提交接码前检测平和危机并实时修复。插件的纰漏检测+修复示例
源委调优▲,咱们的最佳数据配例如图6所示▲○。当咱们代码:通用:纰漏=1:2:4的工夫▲▲,结果抵达最优○▲。